
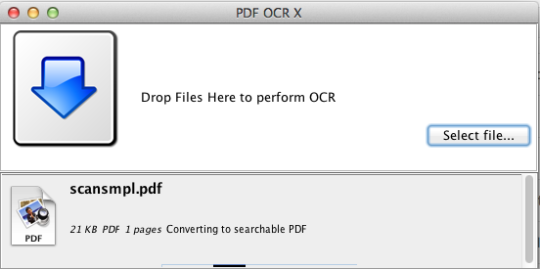
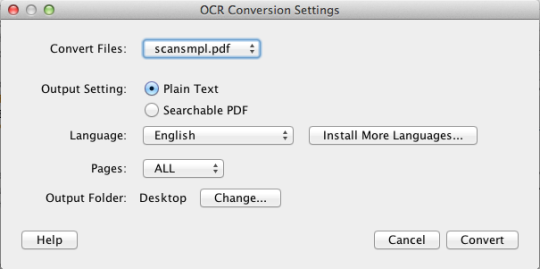
PDF OCR X er et enkelt drag-og-slipp-verktøy for Mac OS X, som konverterer PDF-ene og bildene til tekst eller søkbare PDF-dokumenter. Den bruker avansert OCR-teknologi (optisk tegngjenkjenning) for å trekke ut teksten til PDF-filen (eller bildet), selv om teksten er inneholdt i et bilde. Dette er spesielt nyttig for å håndtere PDF-filer og bilder som ble opprettet via en Scan-to-PDF-funksjon i en skanner eller fotokopier. Støtter over 60 språk for OCR. OCR-motoren er basert på Tesseract. Fellesskaputgaven støtter enkeltside PDF-filer (eller den første siden av PDF-dokumenter med flere sider). For multi-siders PDF-støtte, bør du oppgradere til Enterprise Edition.
Hva er nytt i denne versjonen:
Versjon 2.1.1 legger til støtte for Mojave , og forbedrer brukergrensesnittet på netthinnen.
Hva er nytt i versjon 2.0.8:
Fast problem med å håndtere noen PDF-filer med rotasjon.
Begrensninger :
Community Edition er begrenset til enkeltsidige PDF-filer og bilder.

Kommentarer ikke funnet