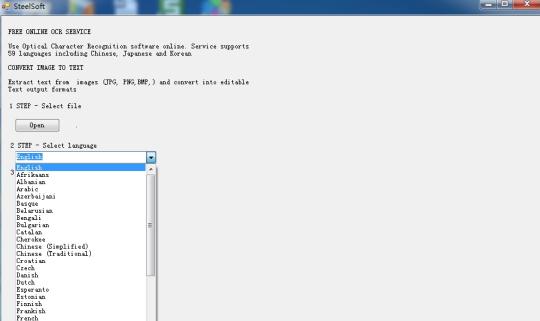
Gjenkjenn tekst fra bilder ved hjelp av Tesseract OCR Engine basert på skyen teknologi.
Bruk Optical Character Recognition programvare på Internett. Tjenesten støtter 59 språk, inkludert kinesisk, japansk og koreansk. Trekke ut tekst fra bilder (JPG, PNG, BMP, TIF) og konvertere til redigerbar tekst formater.
Den er basert på cloud-teknologi, og svært kjent OCR-motoren (Tesseract OCR Engine), så det er bare hundrevis av KB i størrelse, men det kan trekke ut tekst i 59 språk, fra bildene.
Den støtter flere språk: bulgarsk, katalansk, tsjekkisk, dansk, nederlandsk, engelsk, finsk, fransk, tysk, gresk, ungarsk, indonesisk, italiensk, latvisk, litauisk, norsk, polsk, portugisisk, rumensk, russisk, serbisk, slovakisk, slovensk , spansk, svensk, tagalog, tyrkisk, ukrainsk, vietnamesisk etc
Hva er nytt i denne utgaven..
Versjon 5.0 inkluderer UE forbedringer

Kommentarer ikke funnet