Acovea implementerer en genetisk algoritme for å finne de "beste" alternativer for å kompilere programmer med GCC C og C ++ kompilatorer.
ACOVEA (Analyse av Iler alternativer via Evolutionary algoritme) implementerer en genetisk algoritme for å finne de "beste" alternativer for å kompilere programmer med GNU Compiler Collection (GCC) C og C ++ kompilatorer.
"Best" i denne sammenheng, er definert som de alternativene som produserer den raskeste kjørbare program fra en gitt kildekoden. Acovea er et C ++ rammeverk som kan utvides til å teste andre programmeringsspråk og non-GCC kompilatorer.
Jeg ser for meg Acovea som et optimaliseringsverktøy, lignende i hensikt å profilering. Tradisjonell funksjonsnivået profilering identifiserer algoritmene mest innflytelsesrike i et program ytelse; Acovea brukes deretter til de algoritmer for å finne kompilatoren flagg og alternativer som genererer den raskeste koden.
Acovea er også nyttig for å teste kombinasjoner av flagg for pessimistisk interaksjoner, og for testing av påliteligheten av kompilatoren.
Moderne programvare er vanskelig å forstå og kontrollere etter tradisjonelle metoder. Millioner av linjer med kode produsere programmer som inneholder intrikate interaksjoner, trosse enkel beskrivelse eller brute-force etterforskning.
En guidet, deterministisk tilnærming til testing er avhengig av menneskelig testere å se for seg alle mulige kombinasjoner av handlinger - et urealistisk forslag gitt programvare kompleksitet. Likevel, til tross at kompleksitet trenger vi svar på viktige spørsmål om moderne storskala programvare.
Hva slags viktige spørsmål? Tenk på GNU Compiler Collection. Jeg skriver artikler som referansekode generasjon, en oppgave full av problemer på grunn av de utallige alternativer som tilbys av ulike kompilatorer. For mine benchmarks å ha noen mening, må jeg vite hvilken kombinasjon av alternativer produserer den raskeste koden for en gitt applikasjon.
Finne den "beste" sett med alternativer høres ut som en enkel oppgave, gitt omfanget av GCC dokumentasjon og den konvensjonelle visdom av GCC utviklermiljøet. Ah, hvis det bare var så enkelt! Dokumentasjonen GCC, mens omfattende, er også ærlig upresis.
Jeg setter pris på denne stilen av dokumentasjon; i motsetning til mange kommersielle leverandører, som gjør absolutt utsagn om "kvaliteten" på sine produkter, GCC er documenters innrømme usikkerhet i hvordan ulike alternativer endrer kodegenerering. Faktisk, er kodegenerering helt avhengig av hvilken type program som blir kompilert og målet plattformen. Et alternativ som gir rask kjørbar kode for en kildekoden kan være skadelig for utførelsen av et annet program.
"Konvensjonell visdom" kommer i innboksen min når jeg publiserer en ny artikkel. Alt fra høflig til insisterende til uhøflig, disse e-postene inneholder motstridende forslag for å produsere raskt kode.
I de aller fleste tilfeller, slike anekdotiske påstander mangler noen formelle bevis for deres gyldighet, og oftere enn ikke, er det foreslått "forbedring" ineffektiv eller skadelig. Det har blitt stadig mer åpenbart at ingen --myself inkludert - vet nøyaktig hvordan alle disse GCC alternativene fungerer sammen i å generere programkode.
Jeg søker den hellige gral av optimalisering - men nøyaktig hva er optimalisering? Forstå problemet er første skritt i å finne en løsning.
Optimalisering forsøk på å fremstille det "beste" maskinkode fra kildekoden. "Best" betyr forskjellige ting for forskjellige programmer; en database spader biter av informasjon, mens en vitenskapelig bruk er opptatt av raske og nøyaktige resultater; den første bekymring for et innebygd system kan være koden størrelse.
Og det er fullt mulig at liten kode er rask, eller raskt kode nøyaktig. Optimalisering er langt fra å være en eksakt vitenskap, gitt mangfoldet av hardware og software konfigurasjoner.
En optimaliseringsalgoritme kan være så enkelt som å fjerne en løkke invariant, eller så kompleks som undersøker et helt program for å eliminere globale felles underuttrykk. Mange optimaliseringer endre hva programmereren skrev til en mer effektiv form, som produserer samme resultat, mens endre underliggende detaljer for effektivitet; andre "optimaliseringer" produsere kode som bruker spesifikke egenskaper ved den underliggende maskinvaren, for eksempel spesielle instruksjonssett.
Minne arkitekturer, rørledninger, både på og utenfor chip cacher - påvirke all kode ytelse på måter som ikke er opplagt for programmerere å bruke et høyt nivå språk. En optimalisering som kan synes å produsere raskere kode kan faktisk skape store kode som fører til mer cache bom, og dermed nedverdigende ytelse.
Selv den beste hånden-tunet C-kode inneholder områder av tolkning; det er ingen absolutt, en-til-en korrespondanse mellom C uttalelser og maskininstruksjoner. Nesten enhver sekvens av kildekoden kan kompileres inn i forskjellige - men tilsvarende funksjonalitet - maskin instruksjon bekker med ulik størrelse og ytelse egenskaper.
Inlining funksjoner er et klassisk eksempel på dette fenomenet: erstatte en samtale til en funksjon med funksjonskoden i seg selv kan gi en raskere program, men kan også øke program størrelse. Økt størrelse program, kan i sin tur hindrer en algoritme fra montering inne høyhastighets cache-minne, og dermed bremse et program på grunn av cache bom.
Legg merke til min bruk av beltebil ordet "kan" - inlining små funksjoner noen ganger tillater andre optimaliseringsalgoritmer en mulighet til ytterligere å forbedre koden for lokale forhold, produsere raskere og mindre kode.
Optimalisering er ikke enkel eller åpenbare, og kombinasjoner av algoritmene kan føre til uventede resultater. Hvilket bringer meg tilbake til spørsmålet: For en gitt applikasjon, hva er den mest effektive optimalisering alternativer?
Hva er nytt i denne versjonen:
· Små endringer i den ikke-fri lisens.
· Støtte har blitt lagt for de nyeste versjonene av libcoyotl og libevocosm.
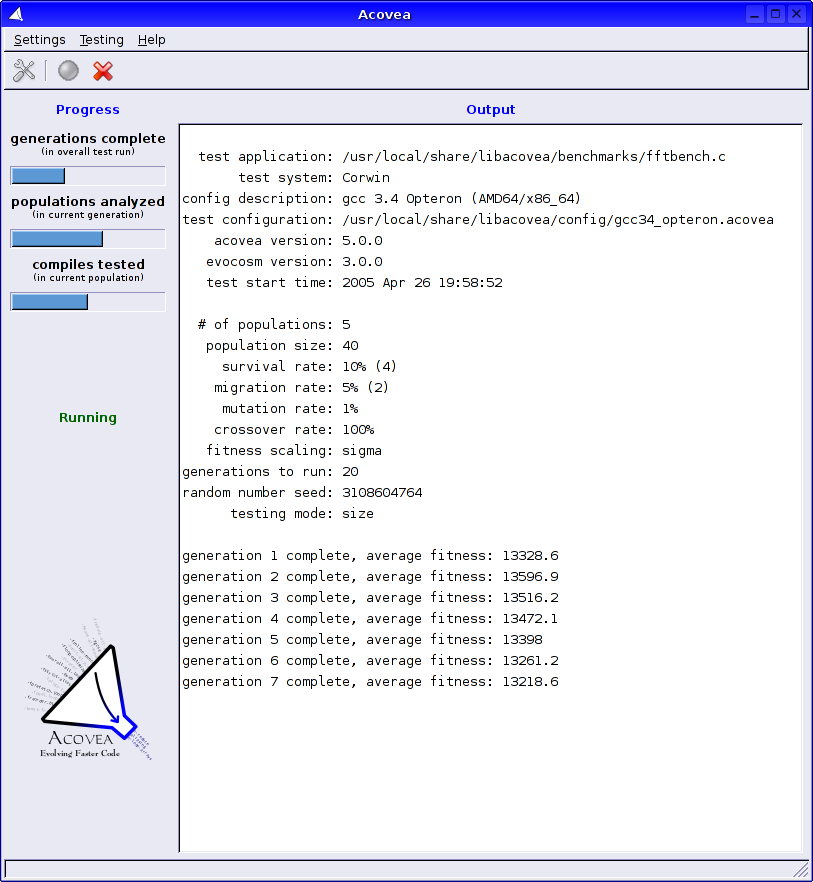
Skjermbilde programvare:
Prog.varedetaljer:
Kommentarer ikke funnet