Free OCR programvare for å trekke ut tekst fra bildefiler og PDF-elementer. Et grafisk brukergrensesnitt (GUI) for Tesseract OCR-motoren.
Søknaden er enkel å installere og, enda viktigere, gratis å bruke, open-source og 100% adware og spyware gratis.
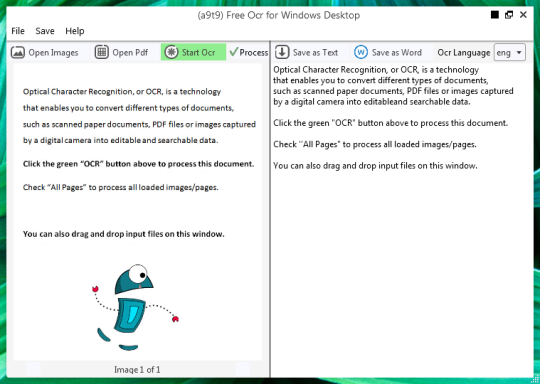
Du kan åpne et bilde eller en PDF-fil. Innholdet i kildefilen vil vises i det venstre vinduet. Hvis dokumentet som mer enn én side, eller hvis du åpnet flersidige dokumenter, bruke pilene nederst for å bytte mellom dem,
Du starter OCR ved å klikke på den grønne knappen OCR, og du vil se resultatet i den andre høyre vinduet. Utgang tekst kan lagres som en tekstfil eller Word-dokument.
Dessverre er konverteringskvaliteten ikke så stor. Bak scenen bruker den Tesseract open-source OCR-motoren. Kvaliteten varierer fra språk til språk -. Så gå videre og teste om det er tilstrekkelig for dine behov
For programvareutviklere og geeks: The Free OCR for Windows Desktop verktøyet er hovedsakelig et grafisk brukergrensesnitt front-end (GUI) for Tesseract OCR-motoren. Den fullstendige kildekoden er tilgjengelig (GPL lisens).
OCR-motoren på programvaren støtter følgende OCR språk: engelsk, fransk, italiensk, tysk, spansk, brasiliansk portugisisk og nederlandsk. Fra og med versjon 3 det kan gjenkjenne arabisk, bulgarsk, katalansk, kinesisk (forenklet og tradisjonell), kroatisk, tsjekkisk, dansk, nederlandsk, engelsk, tysk (standard og Fraktur script), gresk, finsk, fransk, hebraisk, hindi, ungarsk, indonesisk, italiensk, japansk, koreansk, latvisk, litauisk, norsk, polsk, portugisisk, rumensk, russisk, serbisk, slovakisk (standard og Fraktur script), slovensk, spansk, svensk, tagalog, tamil, thai, tyrkisk, ukrainsk og vietnamesisk.
Kommentarer ikke funnet