uni2ascii og ascii2uni konvertere mellom UTF-8 Unicode og noen av en rekke 7-bits ASCII-ekvivalenter inkludert: heksadesimale og desimaltall HTML numerisk karakter referanser, u-rømming, standard heksadesimale, og rå heksadesimale.
Slike ASCII ekvivalenter er nyttige når inkludert Unicode tekst i programkilde, når du skriver inn tekst i Web-programmer som kan håndtere Unicode tegnsett, men ikke 8-bit trygt, og når debugging.
Unicode rømming tilgjengelig er:
- HTML heksadesimale tall karakter referanser (f.eks)
- HTML desimaltall numerisk karakter referanser (f.eks ȳ)
- U-rømming, som brukes i Python (f.eks u00E9)
- u-rømming innenfor BMP og U-rømming utover BMP, f.eks u00E9 men U00010024.
- U -escapes (f.eks U 00E9)
- U-rømming (f.eks U00E9)
- U-rømming (f.eks u00E9)
- U-rømming innenfor vinkelparenteser (f.eks)
- X-rømming (f.eks x00E9)
- X-rømming med tannregulering (f.eks x {00E9})
- Standard heksadesimale (f.eks 0x00E9)
- Raw heksadesimale (f.eks 00E9)
uni2ascii aksepterer et kommandolinjeflagg avgjøre om å generere store bokstaver AF eller små bokstaver af som heksadesimale sifre siden noen enkelte programmer godtar bare det ene eller det andre. ascii2uni aksepterer heller.
I tilfelle av uni2ascii Som standard er bare tegn utenfor ASCII-området konvertert. Selv om ASCII-tegn er også konvertert, er linjeskift bevares hvis deres konvertering er eksplisitt bedt om. Mellomrom er også bevart mindre konvertering er eksplisitt bedt om. I tilfellet med de tre ikke-ASCII mellomrom (etiopisk ord plass, Ogham plass, og ideographic plass), hvis plassen tegn som ikke er konvertert, disse er erstattet med ASCII plass (0x20) for å holde produksjonen i 7- bit ASCII-området.
Denne pakken inneholder fire programmer. Hovedprogrammet er uni2ascii. Det er skrevet i C og må kompileres. uni2html.py er forløperen til uni2ascii. Som det står skrevet i Python, trenger det ikke å bli utarbeidet og skal kjøre på omtrent alle nåværende datamaskin. uni2ascii ellers er overlegen i at:
- Det genererer et bredere spekter av formater.
- Det er omtrent 20 ganger raskere.
- Det håndterer innspill i full 32 bit Unicode range. I motsetning til dette, behandler kun den uni2html
Basic Multilingual Plane (Plane 0) fordi i dag Python representerer Unicode kodet tekst internt ved hjelp av 16-bits heltall. Hvis du har tekst i for eksempel Linear B eller Ugaritic, må du uni2ascii.
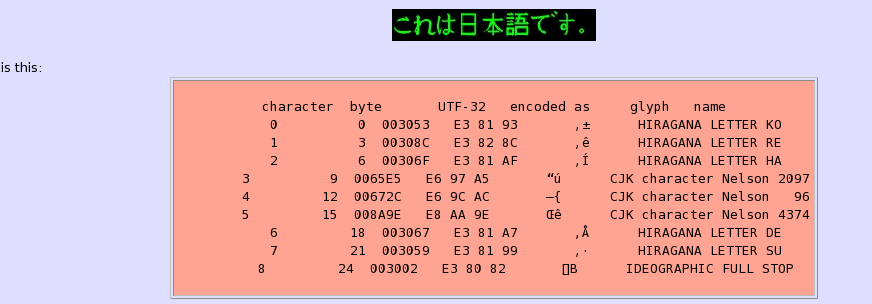
Det gjør en bedre jobb med å rapportere feil. Hvis det oppstår en feil i sitt innspill, slik som mal-formet UTF-8, rapporteres det plasseringen av feil både i form av antall tegn fra begynnelsen av filen (som starter på 0), og i forhold til antall byte fra begynnelsen av filen (også starter på 0). (Karakter teller og bytes er vanligvis ikke den samme siden en UTF-8-kodet tegn opptar fra en til fire bytes.) Kun Python versjon rapporter karakteren teller. uni2ascii gir også informasjon om innholdet av feilen.
Den tredje program, ascii2uni, er den inverse av uni2ascii. Det aksepterer tekst som inneholder en rekke ASCII representasjoner av Unicode tegn og genererer UTF-8 Unicode.
Den fjerde program, ascii2uni.py, leser 7-bit ASCII inneholder u-rømte Unicode, som brukes i Python og Tcl, og konverterer den til UTF-8 Unicode. Det er den opprinnelige program som ascii2uni er en generalisering
Hva er nytt i denne utgaven.
- Rettet feil i uni2ascii som i visse tilfeller subsitution telling var for høy, fikse Debian bug # 626268.
- Lappet å håndtere situasjonen i NetBSD som mangler getline.
- avklart semantikk av ren alternativet som konvertering av tegn i ASCII-området annet enn plass og linjeskift. Rettet feil der dette ble ikke gjennomført på riktig måte for UTF8 typer.
Hva er nytt i versjon 4.17:
- Lagt til uni2ascii følgende konverteringer til nærmeste ascii tilsvar: U 2022 bullet å 'o', U + 00B7 midten prikk til periode, U + 0085 neste linje til Newline, U + 2028 line separator til linjeskift.
Hva er nytt i versjon 4.16:
- The Q-formatet fungerer igjen i ascii2uni .
- Lagt U + 2033 DOUBLE PRIME til tegnene konverteres til deres nærmeste ascii tilsvarende beløp ved hjelp av e-formatet i uni2ascii.
Hva er nytt i versjon 4.15:
- omdøpt endian.h å u2a_endian.h å eliminere konflikt med ekstern endian.h.
- Fjernet kopi av GNU getline fra ascii2uni.c som det er standarden fra POSIX2008.
Hva er nytt i versjon 4.14:
- Fikset en bug som forstyrret med bruk av Q-format i uni2ascii.
- Rettet feil der ascification av U + 2502 og U + 2503 lagt dobbelt anførsels til utgang.
- Fikset en bug hvor -en S alternativet generert en & quot; Omregnet så mange tegn & quot; linje for hver karakter på grunn forlater i debugging av kode.
Hva er nytt i versjon 4.13:
- Rettet feil som førte til at overdreven antall tegn endret til ASCII til rapporteres.
Hva er nytt i versjon 4.12:
- Begge programmene nå tillate inndatafilen navn som skal spesifiseres på kommandolinjen uten omdirigering.
Hva er nytt i versjon 4.11:
- Denne utgivelsen legger til støtte for & lt; XX & gt; & lt; XX & gt; og% uXXXX formater.
Hva er nytt i versjon 4.10:
- Denne versjonen fikser en bug som gjorde Y argument til -en flagg ascii2uni en no-op, og korrigerer man-sidene og hjelp for Y og Q argumenter til et flagg for begge programmene.
- er The Y argument nå en feil for uni2ascii.
- versjonsinformasjonen og handlings oppsummeringer er mer informative.
Kommentarer ikke funnet